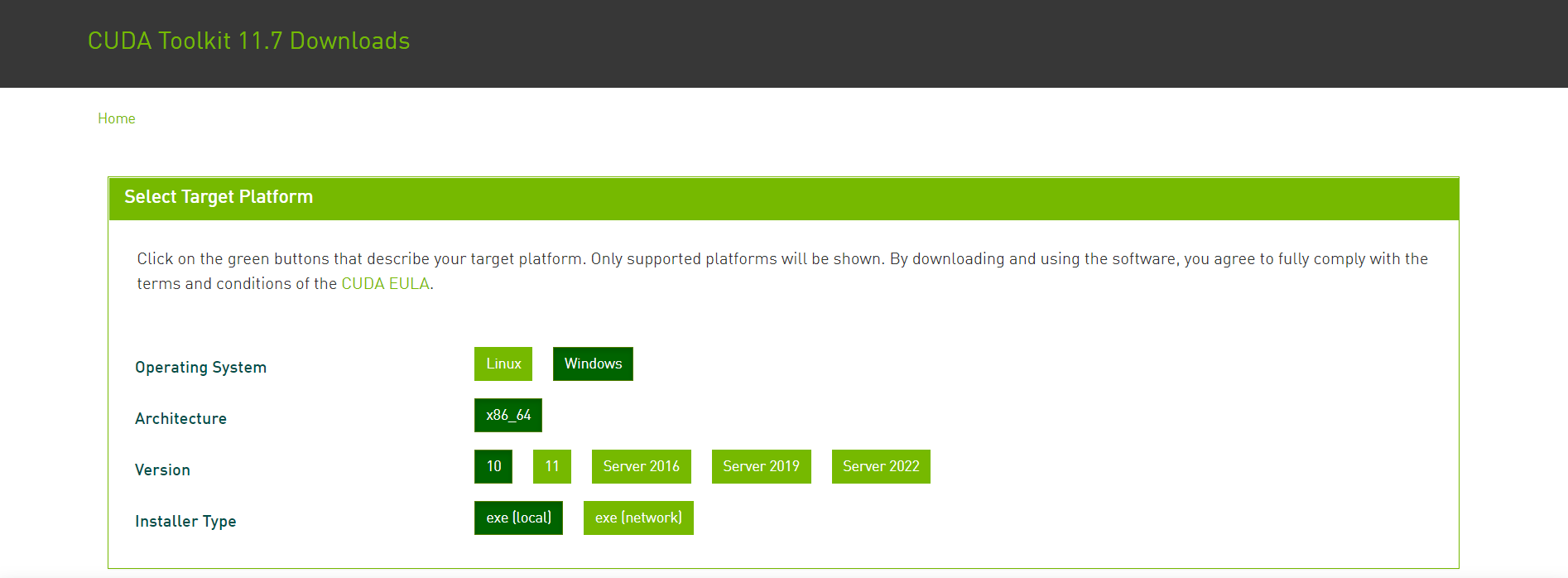
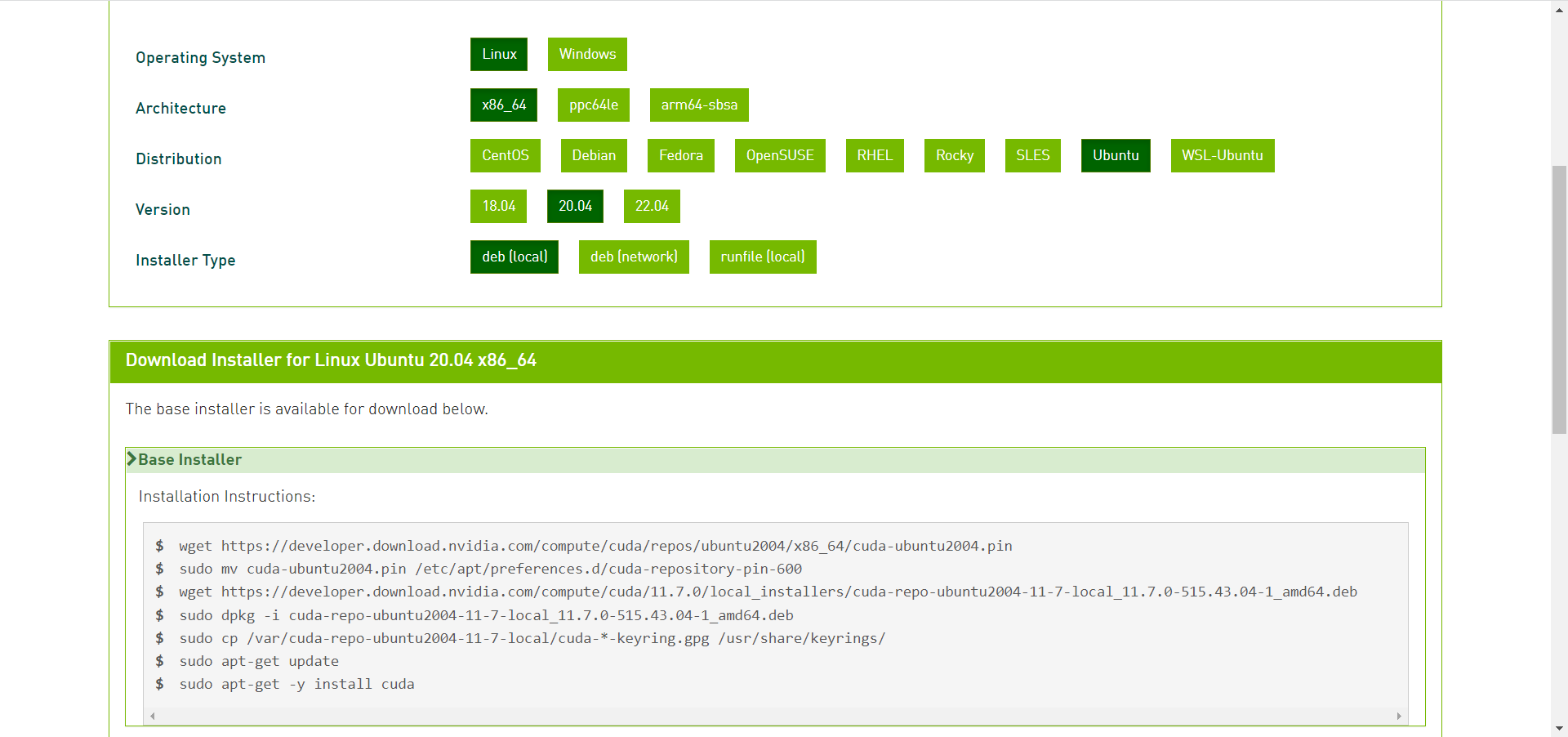
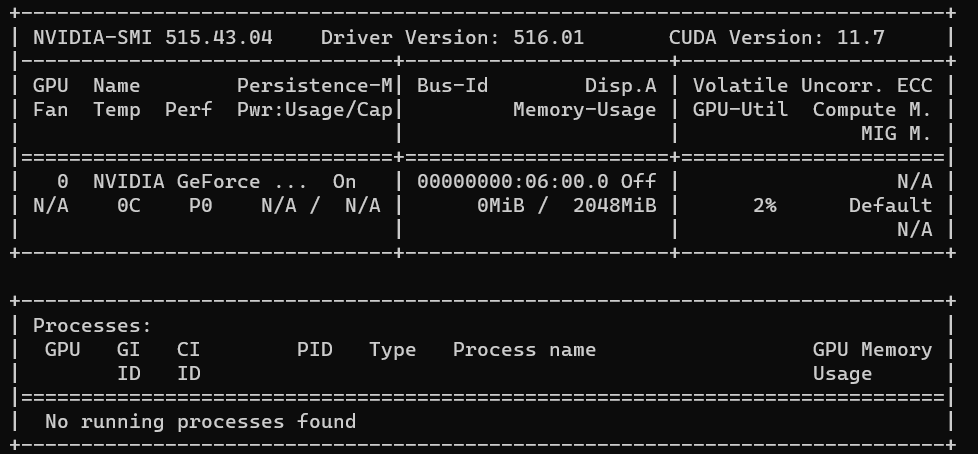
If there is nvida not found, it should be the environmental problem:
Set the environmenal Inside of the .bashrc file, update the path as follows: export PATH="/usr/local/cuda-11.7/bin:$PATH" export LD_LIBRARY_PATH="/usr/local/cuda-11.7/lib64:$LD_LIBRARY_PATH"
Check the nvidia-smi:
1
nvidia-smi
WSL
Check the version of wsl
1
wsl -l -v
Update from wsl 1 to wsl2
change the default version into wsl2.
1
wsl --set-default-version 2
1
wsl.exe --set-version Ubuntu 2
Anaconda
This will show how to install the anaconda at the Ubuntu system:
The first step should be wget the downloaded file:
1 2 3
wget https://repo.anaconda.com/archive/Anaconda3-2022.05-Linux-x86_64.sh # after we downloaded the Linux Version anaconda, we need to run the .sh file, and we just choose yes sh Anaconda3-2022.05-Linux-x86_64.sh
If there is a conda not found problem, we need to fix the environmental variables:
1 2 3 4 5 6 7 8 9 10 11 12
# check the bashrc file vi ~/.bashrc
# insert the path loc export PATH=$PATH:/root/anaconda3/bin/
# excecute file, the conda can be found source ~/.bashrc
# or we can set the environment into true conda config --set auto_activate_base true
Create a Python Env
1 2 3 4 5 6 7 8 9 10 11 12 13 14
# create a conda env name "env_name" conda create -n env_name python=3.8
# activate the env conda activate env_name
# deactivate the env conda deactivate env_name
# create a conda env with environment.yml conda env create --name env_name -f environment.yml
# update the conda env with environment.yml conda env update --name $MYENV -f environment.yml
# from https://github.com/kaldi-asr/kaldi/issues/515 @ willendzw # The env.sh is not under tools/extras/. It is under tools/. So you just need to source env.sh. It just add irstlm path. Eg: export IRSTLM=/home/willen/Documents/kaldi/kaldi/tools/irstlm export PATH=${PATH}:${IRSTLM}/bin
# Connect the ec2 server to ssh ssh -i ...pem ubuntu@Public IPv4 DNS copied # if you are using ubuntu please change the username "ec2-user" into "ubuntu", otherwise just it. ssh -i xiao.pem ec2-user@ec2-3-248-220-97.eu-west-1.compute.amazonaws.com
Librosa
Here is the scripts that installed in case that it will be facing the incompatibale issues for librosa installing.
1 2 3
conda install -c numba numba
conda install -c conda-forge librosa
Here is one example:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
import matplotlib.pyplot as plt import scipy import librosa import numpy as np y, sr = librosa.load("/mnt/c/Users/ABC/SPTK/egs/analysis_synthesis/lpc/data.org.wav", duration=0.020)
a = librosa.lpc(y, order=4) b = np.hstack([[0], -1 * a[1:]])