Speech Synthesis Toolkits Introduction
About TTS (Text to Speech)
The first thing is about text analysis process
- Word division, annotation, lexical annotation, rhyme prediction, etc.
- Representation of normalized transcripts as phoneme-level text features
- The length M of text features is only related to the transcript itself, not to the speech duration.
We are usually talk about the stastical Speech Synthesis. After we doing the text analysis, we will just get into the acoustic generation part.
Duration Model
The input will be the HMM output labels and transform into one-hot features, along with the statistical features.
Output will be the phone duration and the time of the states. In HMM, we will get a frame level alignment.
Acoustic Model
The input will be the frame level info, the output will be the spectrum params, the f0, along with the vowels, and consonants. After feeding those params into the vocoder, we will get the speech.
For every statistical model, the most important parts can be: the acoustic model, and vocoder.
Acoustic Generation
HMM based acoustic model
Text Analysis
Here the text shows the start time and end time of the phone starts and stops. The start time and end time is from the HMM model alignment. And in decoding part we can decode the time for each phone.

NN(seq2seq, end2end) based acoustic model - Tactron
Text Analysis
And this is the full information to show how each phone’s prodacy infomation. That is how it different from the HMM model since it does not need to really record all the starting point and ending point of each phone. Thats the core difference between the previous model and latest way.
In tactron, we can just use the CBHG to do the pre-decoding, to learn the all textual information for the trainning text corpus, like grammar or semantic information.
There are the basic components in Tactron.
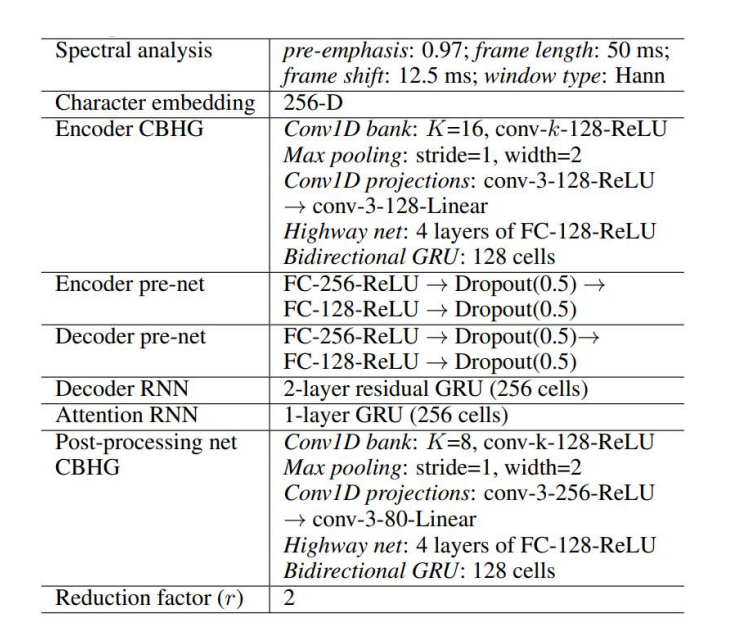
The input text will be the English sentences, for Chinese will just be the Chinese phones. It will use the Mel filter to get the Mel charactersitics.
Tacotron Training
Implementing CBHG Encoder in Tacotron
The Tacotron model based on attention mechanism includes two parts, encoder and decoder with attention mechanism, and this assignment only needs to implement the CBHG-based encoder part.
Data
Based on 10 hours of Chinese data open-sourced by Beibei Technology, we provide the processed text features and packaged them together with the audio files to Baidu.com, download link.
1 | |
In the tacotron directory in testdata, we also provide some data from this database directly to test the process.
Environment
First execute pip install -r requirement.txt to install the required environment, which is also the test environment for this job.
Due to the large number of parameters in this network, it is recommended to use a server with a GPU for training tests.
Procedure
First, in the egs/example directory, run bash preprocess.sh 4 to extract features from the text and speech data in the target testdata.
After the feature extraction, run bash train.sh to train the model. The error is in models/basic_model.py, which is where we need to implement the CBHG encoder part of Tacotron.
Once the CBHG implementation is complete, training can be performed directly.
After the training is complete, a synthesis script is written to test it, modeled after egs/example/synthesis.sh. Since the attention mechanism used at this point is the most primitive attention mechanism mentioned in the code explanation, the convergence performance and effect are poor. In the next assignment we will implement a more stable Tacotron system.
Traditional TTS model Training Demo(duration model, acoustic model)
Text features -> duration model -> acoustic model -> world vocoder -> audio
1、Download data, configure environment
Download data
Data link: https://pan.baidu.com/s/1_zN-PSIIrxtCGvjo1TWz1g
Extraction code: jbc5
Unzip the train_data folder
Data link: https://pan.baidu.com/s/1i28ZppgWYHIupk8piH7SyQ
Extraction code: mvkj
Configure environment (Python 3.6 Tensorflow 1.12)
Install python package
1 | |
If you are slow to install, you can use whl to install
tensorflow 1.12 whl package: https://pan.baidu.com/s/1WCOyFhszJnHHtIMWBq0sxQ
Extraction code: r73i
2. Normalize data
Normalize the duration and acoustic input and output data to get the train_cmvn_dur.npz and train_cmvn_spss.npz files in cmvn.
1 | |
3. Write the model
Complete the AcousticModel and DurationModel model definition section in model.py
The model inputs are inputs and input_length, and the predicted results are targets
inputs are the input features, input_length is the first dimension of inputs, targets is the prediction result
Inputs and outputs
inputs.shape = [seq_length, feature_dim]
input_length = seq_length
target.shape = [seq_length, target_dim]
The input feature_dim of the time-length model is 617 dimensions, which represents the text feature.
The target_dim of the output of the duration model is 5 dimensions, which represents the state duration information of each phoneme
The input of the acoustic model has a feature_dim of 626 dimensions, which represents the text features and the position features of the frame
The output of the acoustic model has a target_dim of 75 dimensions, which represents the acoustic features of the target audio (lf0,mgc,bap)
Task description
Write the model to predict the output targets based on the input inputs
4. Training
Train the duration model
1 | |
Train the acoustic model
1 | |
The training model results are saved in logdir_dur and logdir_acoustic respectively
The total number of training steps, checkpoint steps, etc. can be modified in hparams.py. The model convergence can be judged by the loss curve and the effect of test synthesis, not necessarily by the total number of steps run.
the loss function curve by tensorborad
1 | |
Open browser to view local port 6006
5. Test synthesis
The predicted output of the duration model is in output_dur (as input to the acoustic model)
The predicted result of the acoustic model is in output_acoustic (lf0, bap, mgc folders for the corresponding features generated, according to which the audio in syn_wav is synthesized by the world vocoder)
<checkpoint> Fill in the path of the model obtained by training
1. Test the acoustic model (using real duration data)
The first parameter of the test script is the input label path, the second parameter is the output path, and the third parameter is the trained model path (e.g.: logdir_acoustic/model/model.ckpt-2000)
1 | |
2. Test duration model + acoustic model (use the output of the duration model as input to the acoustic model)
1 | |
The final synthesized voice is in output_acoustic/syn_wav
Vocoder
Source Filter Vocoder: Use World as an example
Source Filter Vocoder made use of the source filter theory. There has some open-resource vocoders like:
HTS Vocoder
Griffin-Lim Vocoder: Converst Mel Spectogram into the speech audio file.
Staright: https://github.com/shuaijiang/STRAIGHT http://www.isc.meiji.ac.jp/~mmorise/straight/english/introductions.html
World: https://github.com/mmorise/World
World is a very popular and latest open resource vocoder project on github. WORLD corresponds to the following three acoustic characteristics: F0 fundamental frequency (F0基频), SP spectral envelope(SP频谱包络) and AP non-periodic sequence (AP非周期序列).
The lowest frequency sine wave of the original signal composed of sine waves is the fundamental frequency.
Spectral envelope is the envelope obtained by connecting the highest points of amplitudes of different frequencies by a smooth curve.
The non-periodic sequence corresponds to the non-periodic pulse sequence of the mixed excitation part.
Install the World
git clone
1 | |
compile
1 | |
The compilation process may take a while, so please be patient and get the tools/bin folder after compiling

copy synthesis
Synthesize syn.wav with world vocoder based on input test.wav
Extract f0, sp, ap from test.wav using world, then synthesize copy_synthesize/16k_wav_syn/000001.resyn.wav based on the extracted features
Sample rate 16k
1 | |
sample rate 48k
Modify on the basis of copy_synthesis_world_16k.sh, you can modify parameters as input and output paths (wav_dir\out_dir), sample rate fs, mcsize, etc
(optional) melspectrogram copy synthesis
Synthesize syn_mel.wav from input test.wav via griffinlim
Extract the melspectrogram of test.wav using world, then synthesize copy_synthesize/syn_mel.wav based on the extracted melspectrogram features
1 | |
NN based Vocoder
Tacotron TTS
Tacotron Hands-on
Clone the code
1 | |
Or we can clone here:
1 | |
ESPNET Text to Speech
Install ESPNET
1 | |