Audio and speech Processing Theory
Audio Processing
ADC (Analog to Digital Codec)

After the Microphone got the analog signals from the environment, it will pass through the codec and transform it into the digital data which only has “0”, and “1”.
The signals that continually trace the same path in this way are called periodic.
The shape that repeats is called a cycle, and the time it takes to repeat is called the period.
$$
f = \frac{1}{p}
(f: freq, p: period)\
f = rate * channel.num * sample.bits
$$
$$
dur(sec) = \frac{bit.num}{bit/sec}
$$
$$
dur(sec) = \frac{size(mb) * 8 * 1024 * 1024}{sample.rate * bit.depth * channel.num }
$$
If there is 16 bit mono speech file:
$$
dur(sec) = \frac{size(mb) * 8 * 1024 * 1024}{sample.rate * 16 * 1 }
$$
The sawtooth waveform is important in the study of production, as the vocal cords change the airflow from the lungs into a signal that looks similar to a sawtooth.
Square wave, or rectangle wave, or pulse trains. The signals differ in how long they stay at the top and bottom of their travel, their duty cycle (the proportion of period in which they are at their maximum).
Each of these lasts for a short time only, and hence they are known as transients (since they don’t hang around). Burst is happened in the human speech and they are part of the transients.
The rms amplitude is the most important way of specifying the amplitude of a signal because it presupposes the use of a related quantity - intensity.
http://soundfile.sapp.org/doc/WaveFormat/
Audio Architecture
We will use the SDL C++ lib package to explain this, and we will know from this that how computer render the audio files.
The most high level concept or the interface of the audio system from the SDL is the IAudioContext.
IAudioContext
The IAudioConext contains those operations:
1 | |
Another component is like IAudioDevice, it includes:
1 | |
We will also have an abstract idea, like there has AudioObject. This is the object of our audio system.
It includes:
1 | |
We got IAudioData to contain the audio data, they are generated from: GenerateSamples(stream, len, Pos, SampleInfo).
Speech and Language Processing
Here are the lifecycle of the speech features processing.
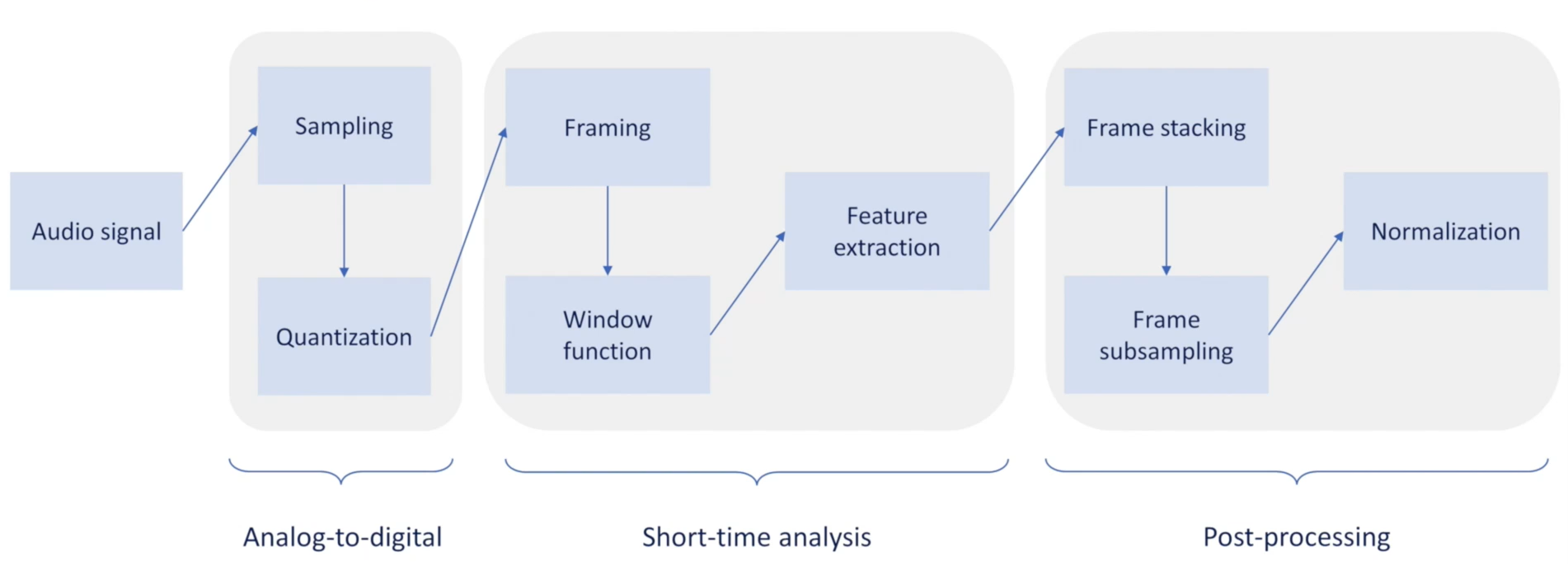
Short time analysis : Speech Features
The feature in speech means that an indivisual measurable property or characteristics of a phenomenon being observed.
The three principles of a good feature:
1 | |
Short time analysis
The basic idea is to break the audio frames into small trunks, which range from 10ms ~ 30ms, so we will think in a more micro way. In this way, each trunk will be stationary. And those trunks we will call it frames. In video processing, each image you captured is a frame, but in speech processing, we will only know the dense samples since we only use the frame for analyzing.
Framing
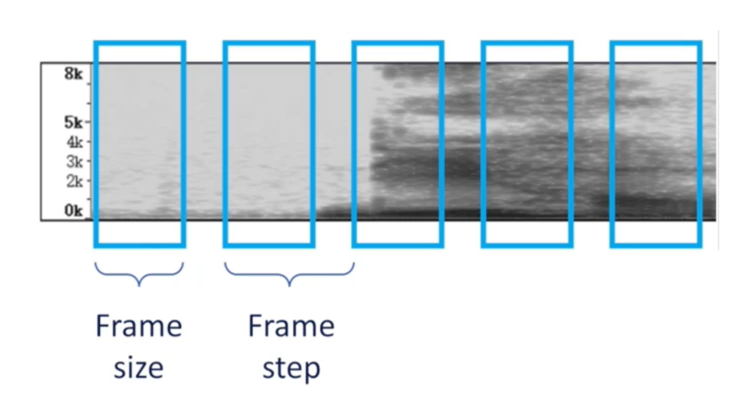
There are two concepts from the framing:
- frame size: the duration of each frame
- frame step/stride: the temporal distance between two consecutive frames
Three principles of framing:
- Size > Step (Mostly used way, so they can share overlaps)
- Size = Step (So each sampling point only belongs to a specific frame)
- Size < Step (So there may have gaps between different frames, which is not suggested since it can lose some info)
Eg:
1 | |
Window function
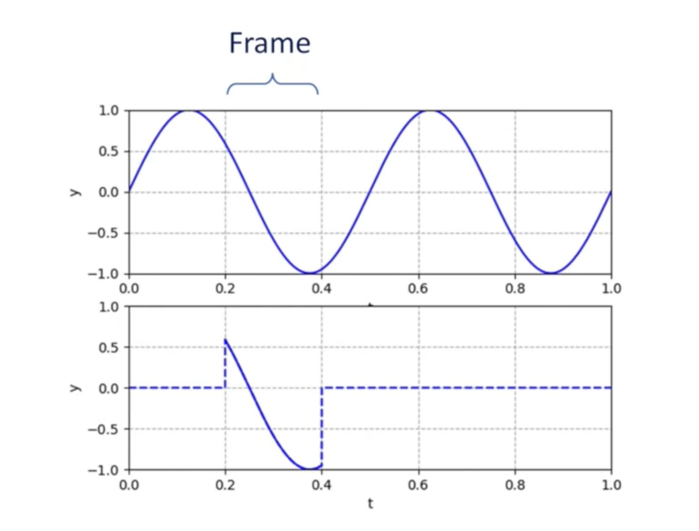
In order to solve the framing discontinuity problem, we need to use the windowing function. Because when we do the framing, it will make the original speech signal with no boundary connections, which can cause discontinuity (Gibbs Phenomenon: undesired high frequency components and spectral leakage).
The logic of the windowing function is to give each frame a weight, near the edge values we make it close to 0, if in the middle frame, we keep it untouched. 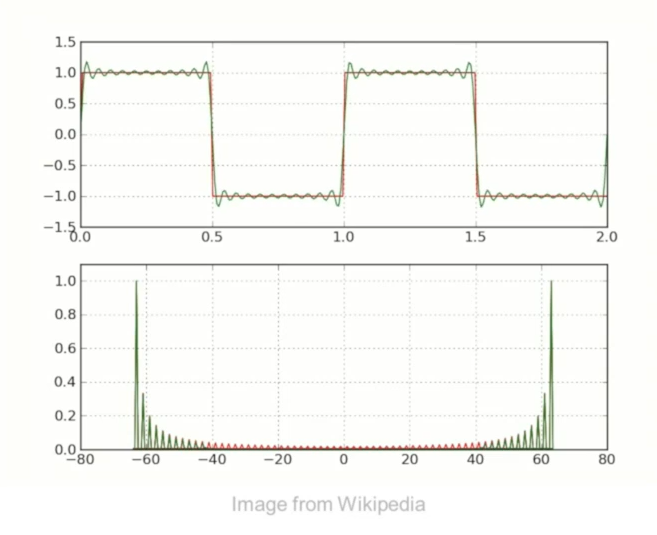
Gaussian Windowing
Hanning Windowing & Hamming Windowing
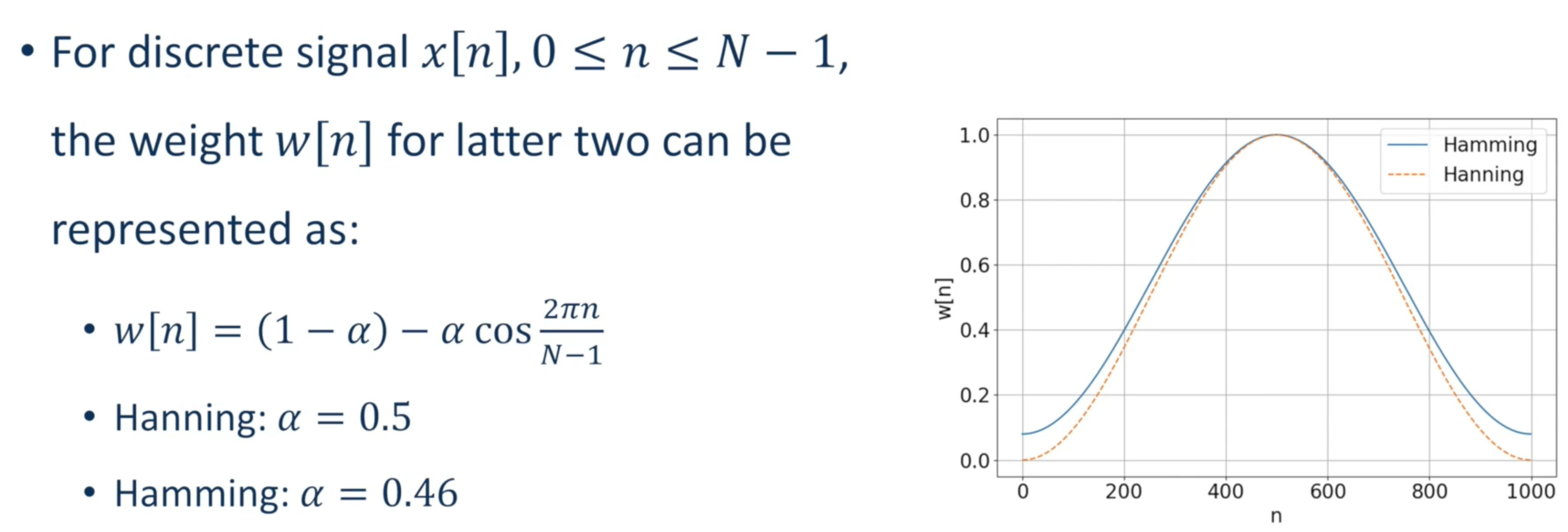
Hamming windowing will set the edge totally like close to 0, but hamming window will slightly not that harsh.
Frame Post Processing
After we did the framing and the windowing, we need to do some frame post processing.
They includes:
- Frame Stacking : Stacking the neighboring frames into a single super frame, it will combine the relevant frames into a bigger frame.
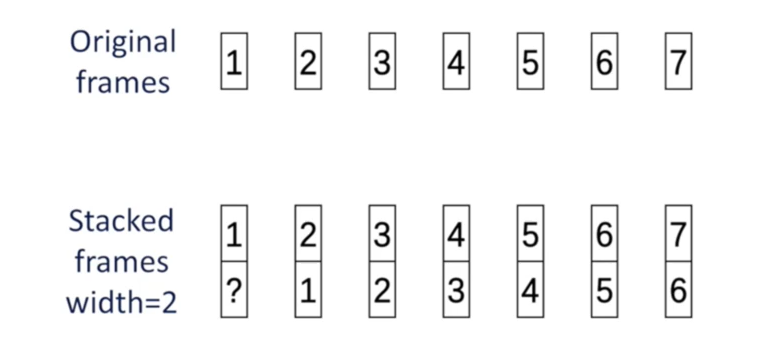
As shown it will copy each frame from the previous frame, it will help us to know more information from the previous frame. The ? frame from the graph can be replaced by 1st frame.
- Frame Subsampling: Drop some frame.
It will help us to reduce the computational cost.
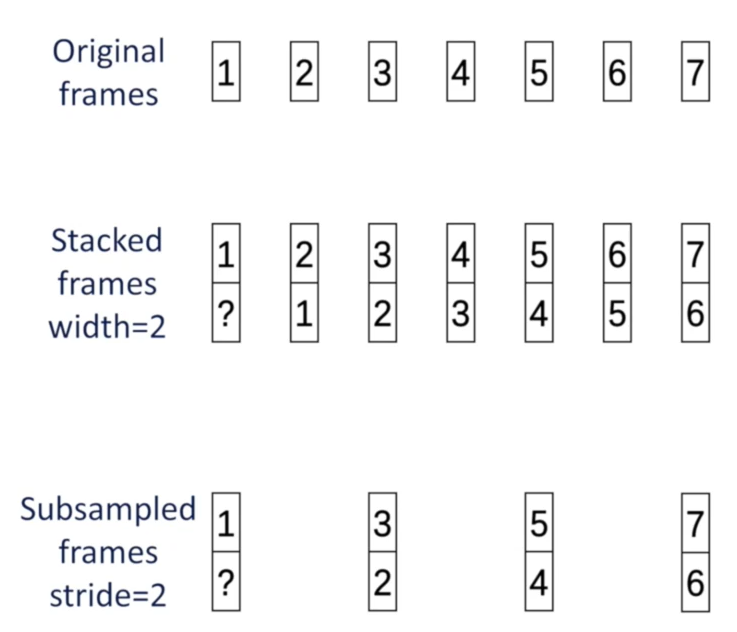
We mostly do the Frame Stacking and then is the Frame Subsampling.
- Frame Normalization: Optimize the numeric values to follow the Normal Distributions.

The normalization parts helped us to converge when we do the training.

Feature Extraction
Global Acoustic Features (Stationary features)
The global acoustic features are mostly stationary features, since we always need to get the whole audio files then can we processing those features.
Also if the speech signal is very periodic signal which are very stable, then it is very useful to discuss about those global acoustic features. But to many speech signals they are not periodic, if we use the stationary features to describe the whole speech signal, which will lose some details of the speech. And another question could be, the stationary features will be extremely sensible to the noise.
Fundamental frequency (f0)
Formants (f1 and f2)
Intensity
Time Domain Features
We can extract the features directly from the waveform without the Fourier transform.
Here are the usual time domain features:
Short Time Energy
It mostly used in VAD, if high energy => speech signal, and in Automatic Gain Control (AGC).
Short Time Average Magnitude
Short-time Zero Cross Rate (ZCR)
Short-time Autocorrelation
We will delay the signals by k samples, then compute the correlation.
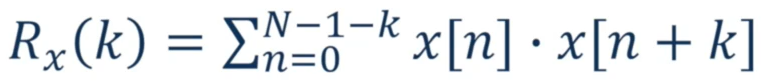
We will mostly use this in the pitch detection!
Short-time average magnitude difference function (AMDF)
We will delay the signals by k samples, then compute the difference.
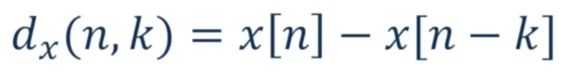
For the short-time AMDF, we use:
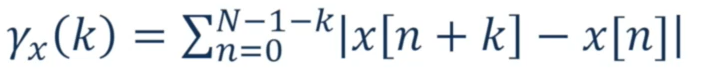
It just like the autocorrelation, but it is very good for the pitch dection.
Short Time Linear Predictive Coding (LPC)
We will assume that each sample can be approximated by previous samples via linear combinations:
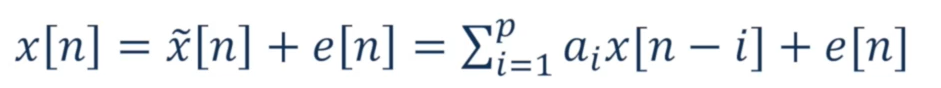
$$
The \ combination \ of \ the \ previous \ ks \ samples : a_{i} \
the \ difference : e[n] \
Each \ frame \ has \ N \ Samples
$$
Frequency Domain Features
We need to do the Fourier transform firstly, and this is always be used.
Speech Production Model
The voiced and unvoiced speech mostly for 10~20 ms.
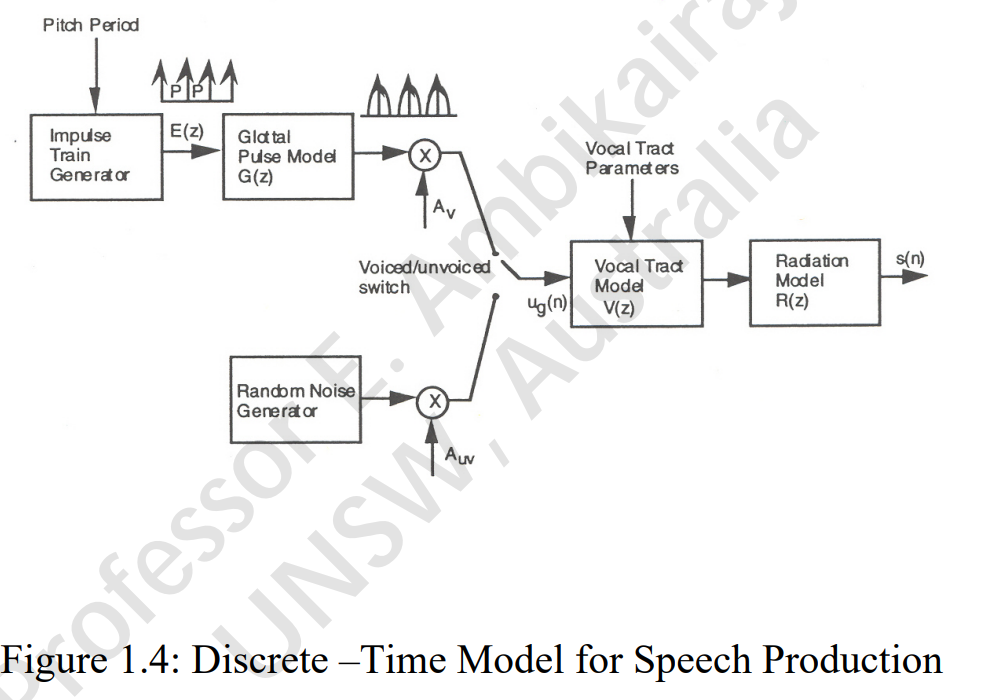
The vocal tract model can be understood by a filter equation, here can be the transfer function, the n means the filers you want to have:
$$
\frac{1}{1 + b_{1}z^{-1} + b_{2}z^{-2} + b_{n}z^{-n} }
$$
The Radiation model here means the lip model.
Vocal fold can become a signal system. It has a input signal, and transmitted into a system and output a processed speech signals. So if in vocal tract, it will be the voice source signal, and pass the vocal tract it will be the speech signal.
The human speech model can be a LTI (Linear Time Invariant) system. LTI system can be both linear and time-invariant, and can be homogenous (k * input signal and k * output signal, which can be a linear addiction, in a, frequency is the same, when got statuation or overanged it could be not LTI system) and additive (sum of the two signals, signals can be added and transferred). Linear can be = homogeneity + additivity.
A system that is time-invariant does not change over time, in (t-delay) => out (t-delay). For a sinusoid, a change in time is equivalent to a change in phase, a sin wave and a cosine wave differes only in time.
We will assume the vocal tract is a LTI system, but in reality it is not, we just gave an assumption, it is time-variant. We are treating some vocal tract noise into a LTI system.
But we only need to know the response of an LTI system to sinusoids.
www.speechandhearing.net/laboratory/esystem/
For LTI system, if the input is the sin wave, the output will be the same freq sin wav but can be differs in amplitude and phase.
Frequency response can be with amplitude response A(f) = Outamp(f)/Inamp(f) and frequency response.
Like the amplitude response, like for voltage, we can get the gain is theA(f) = Voltage_outputamp(f)/Voltage_Inputamp(f),
and we can get more acoustic information by add the 20logA(f), to get the unit under it and units in dB.
1 | |
Today is not Thursday.
Not today is Thursday.
It is false that today is Thursday.
1 | |
Fact 1 implies Fact 2
Fact 2
Therefore, fact 2.
What the smallest unit of a sentence if we are talking in semantics ? Morphones?
Since we are discussing the sentences level. The **sentence?** So the sentence is somekind of reasonable sentences?
Search from the queries like eliminatings the values not met the values and keep the results not met the conditions.
Formal linguistics is caring only about the logic validity.
```f0``` can affect the formants, but mostly it wont but if we use a very "unreasonable" way to pronounce it.
Why we like "h" sound is that it will not affect the vowels after it since you will get some "preparation" for the following sound. Always use your own judgements not only relying on the Praat only.
**For a spectrum, the x-axis is the frequency domain, which can be understood the units of the sine waves in that particular units like 1 KHz actually represends the divisor like 1KHz sine wav signal, the original signal is the dividend. The results that reflected on the y-axis is the dB scale which is dervied from the forier series.**
Fourier synthesis is the multiplication of those sinounds muliple with the fourier series.
Even you changed the first hamonics even you remove it, the fundamental freq will remain the same. Removing the fundamental component (H1), the pitch will not change, it will change a little bit but just the little auditory hearing from our human beings.
amplitude response is used for testing the audio system. System amplitude response can be a filter of the speaker output. The amplitude spectrum is on the ADC processing, the amplitude response can be already the DAC.
Most of the energy of the triangular wave is in the first harmonic.


**there is a Queen: A**
**there is an Ace: B**
**there is an King: C**
$$
1) A \rightarrow B \\
2) C \rightarrow B \\
3) C \vee A
$$
Since:
$$
p \rightarrow q \equiv \sim p \vee q
$$
So:
$$
1) A \rightarrow B \equiv \sim A \vee B \\
2) C \rightarrow B \equiv \sim C \vee B \\
3) C \vee A
$$
Now, we knew: Sentence 0), 3) is true, exactly (1) and (2) is true.
Universal validity (|=)
P |= Q :q is a semantics consequence of P, |= is the knowlege extraction of the knowledge base.
P erro Q
|- : Supports, implies to the deduction system
p -> q
p
_____
If p is true, then q is true, if p is true, then {p->q, p} |- q
Got some knowlege of the world + addtion of the datbase -> knowlege system
**Steady Point:**
**The formants have the highest energy to show the role of itself.** It always in the half or close to the half position of it. For dipthongs, they can have two steady points.
/^/ not totally = [ʊ], but we mostly ignore it.
[^] or [ʊ] there is only little potential differences, only depends on the willingness of the native speaker, like American and British people.
Most English accents differs in the vowels, but the consonants are just little things.
IPA charts does not represent any language, the vowel chart just represents the most "**extremely**" humanly possible position of the sound, just for setting a "**Border**".
Irish Vowels:
heed: i (long, just like i:)
hid: I (short)
One is longer (**phonlogy: length = acoustic duration**), acoustically saying is the duration.
1) Already known, literature review, get the question. 2) see what you found and how and where, auditory , social impacts , and analyze the results in your way 3) results,
F3 formants will be affected by F2 which is the front and back of the tongue, also will be affected by the roundness or unroundness, they will be affected by each other.
Make sure the two pics scale the same.
Make sure to visualize the table with the pic.
M<D, I> , D: domains, I: intereting function of the meaning of the domain
M: Model
!
E : thats a unique exisitance
[]^M = I() : Meaning function, interpreting function.
$$
[]^{M}
$$
Everything got a name:
C: is the name
{i, ii, } the name of the indivisuals.
Finite, and modality: Infinite
We name everything like an object.
**PROPOSE: 1. Choose a measure the complexity**
**Treetagger**
Residual: is the difference between the observation and estimations.
Categorical Perception
Outerear => Convert the acoustics signal into the mechanical signal => Middle Ear
Pinna have some slightly amplifing the acoustic signal a little bit.
The way we are deciding the sound direction is that we had two ears, and the left ear may hear eariler than the right one, so there has time delay, from that delay we can determine, espcially we had two ears together to decide at the same time. Since we had two ears, if we are discussing in the cocktail party in the nosiy environment.
VTL for male is like 18,19cm
Female: 14cm
We have some boosting effect into our ear. Outer ear boost.
Middle ear can act like a low pass filter, and it acts like a transfomer, we need to boost the incoming air pressure. Like you move a rock using the leverage effect. It will boost like 5dB, which is like doubling. The membrane will boost like 25 dB, which is like 20 times (20log(20))dB. Middle ear also protects us against the very loud voice. It regulates the loudness for inner ear.
Speech hearable area is like speech banana. The dip in the hearing curve(absolute hearing threshold) is due to the boosting effect from the auditory system. The y-axis is the sound from the loudspeaker and thats the signal we can calibrate into dBW.
For 1KHz in the sound equal loudness curve for phons its just quite linear.
For low frequency, the sound will perceive more rapidly changing from the human hearing system.
www.ipacharts.com
internationalassociation.org/IPA_charts/IPA-2018.html
i e E a:You can just pronounce from there, so you can feel the idea how you can know the direct difference.
Everything within a set has two sets in it: one set within the set, and another set out of the set.
Relative freq: the freq that divide the sum
X^2 distribution is somekind of like normal distribution.
**Residual is** : o - e, oberservation - estimation, if the residual is positive, the oberserve value will be greater than the expeectation value. Residul probability higher which means **higher interaction**, which means higher portion of that. - is means fewer.
So Kai2 distribution it can tell you which portion may share the highest propotion of it. If the value is higher, which means the freq of it is quite high, which means higher density.
You can describe any parametric data stastisic into two parameters: 1) Mean 2) Standard Derivation (is something like residual)
hm: harmontic mean, is like talking about rate
How to tell ur data is normally distributed?
We can use the p-value.
It is very safe to use the non-parametric instead of prametric test.
T test is based on mean.
Rank order test is testing on rank order, you pick all the relative frequency and rank them.
**"signifance difference"**:
We need to find the n-th (example like 150) most frequent frequency word, and then caculate the word frequency related to that position, so that we can represent each word in the vector form.
Sometimes you remove the stop words, but sometimes u didnt, it really depends on the question you are dealing with.
If we will need to calcualte the sentence level complexity into the sentences, since we can use the context complexity.
Treetagger, R, SPSS ,any libarairy for exapmple like for Kai Square?
APA
chisq.
chisq.test(xtabs(cbind(we,FileTokens-we)~Periods))$observed
chisq.test(xtabs(cbind(we,FileTokens-we)~Periods))$expected
Infinite number of cycles for a perfect siniosoid signal: infinitely narrow in the frequency domain, it would be a line.
So the widebrand or narrowband filter in analog signals, and if in the digitalized way, it would be the window length of the FFT. Wide band filter, poor resolution. Narrow band in someway can be more suffiecient, since we can see the formants more clearly.
In wideband system, the impluse response will be very short, if we wanna analyze the **formants.**
Narrow response will be longer impluse so the timing will be longer, so we can check the indivisual **harmonics**, this always used to track the pitch contour all because the impluse response is very long.
Infinite precision: is to say the way how we say it, its just a ideal way, its not the reality, but we just call it.
Sampling is just mean how many samples within one second.
[] and () is just a way to disperate the discrete and continous time.
^: which it means it just qualitized to the nearest value it sampled. Like rounded.
1/1minsec = 1kHz
Nyquist frequency(**folding frequency**) is > 2 times, but never forget the =, if the = 2 times, thats not enough. Nyquist Rate, more than twice is very important.
44100 => 22050, the 50 Hz is just for bufferring.
Most acoustic energy is under 5KHz.
Nyquist rate (applied to period or un-period signals) is the lowest sampling frequency that retain all the information in the signal. It is different from the Nyquist frequency, nyquist frequency is another concept which just mention about that theory.
Impluse unit train is like a train with multiple trains, its some kind of like impluse unit train. Is also just like a period spectrum, since it followed a period way. Its almost like a discrete signal. Mupltie time domain, and we got the convolution in the frequency domain.
U can always get the negative freq from FFT, usually we ignore them. Every spectrum has its negative part, but we ignore it.
Smapling: is about unit impulse train
We use the anti-aliasing filter to filter any signal that higher than half of the frequency like Nyquist frequency.
Impluse unit train (time domain) convolution frequency domain, and get the FFT spectrum.
16bit audio data: 2^16 (+ and -), it was defined the largest sound we can hear like 130 dB, and the smallest hearing threshold, which is also called the dynamic range.
Dynamic range is from (n*6), so if we need to record the 130dBSPL sound, so we need at least 22 bit audio recorder.
8bit = 1 byte audio quality for one sampling data.
Noise signal + Qualitized signal = Real Signal.
Loudness : Pycohologycal
Equal Loudness: is pychological the same feeling of the sound, so its called the phone.
We just need to know the freq and dB so we can get the equal loundess curve. like 1Khz , 90dB, on that equal loudness curver 90 phons, 4Khz, so on 4KHz, is like 95dB, so psycaological only 4dB difference.
Louness in sones, is 100dB, 1KHz, 100Phons, so we get into the 100 phons euqal curve, and find that what at 1KHz from the curve, which is also 100dB. Also we can do the opposite way.
**40Hz, loundness in sons is 0.1, and its in the 20phons and is 68dB. Also it can be converted into Pascal:**
**P = Pref * 10(68/20) = ...pascal.**
At the first the masking experiment they use like 400Hz masker, but when comes to the same frequency, they will have a dip there, but laterly they improved using the auditory masking by using white noise and which we can say it is the narrow band noise.
Auditory masking at higher freq will be elevated , and the for lower freq the slope is quite linear since it can be dependent from the outer ear filter or boosting filter.
The lower freq hamonics will masking the higher frequencies as well. So it is also a tradeoff, it depends on what you really want.
If we wanna higher frequency, so we can have a frequecny at the same freq, if not we should have the freq lower than that.
The critical band is to set the crtical band that mask the particular sound or freq we want. Critical bandwidth is not depend on the width of it, no matter the width of it. So if we go through the critial bandwith point, so the percieved loudness will be elevated or loudness summation.
The masking phonomenon and tthe loudness summation are two different things, and two sperated phoneon, and they have just few connections with each other.
Am(Amplituded modulation), FM(frequency modulation), they had the same amplitude but have different phase. Am is more detectable than FM.
Ohms acoustics law: people can hear the different hamonices from the complex sound.If the engery is within the critical band, then the loundness will be summarized. So we have one critical band for each frequency, so we can use many bandwiths within a full scale frequency band.
Byle Moore
For complex sound, we need to check if the frequency component in the critical band, the fist thing is to split the sound into critical band, and then do some caculation between those critical sounds to get the percieved loudness.
The masking in some way it is more like deletion, and critical band is more like summation focused, there are a lots of phoenon, And critical bandwith is more like a more general and specific way to expain a lot of sound phoneon like masking. Masking is a very broad phoneon, and its very scentific phoenon.
|- : That is a derivation symbol, from one statement derivated to another.
p(x,y) there is no quatifier (quantification expression), than we can see that as x, and y are two free variables.
Substituion: Replace the words just like in the Microsoft words. We can replace a particular word with a particular word.
#### **Meta languages**
For universal proof, we need to try every element and prove that if it true, then we can prove it is universal.
First order logic is about the indivisual elements within a set, but the second order logic is about the indivisuals with indivisuals like combined into a subset. Relation is just the cross product between the set elements. "For every varibale" can be like first order.
[]^M: M is the model.
c in here is arbitary, and it is just the constant.
The universal in here is that mean we can choose any universal element/constant we want. Every means not leave anyone behind.
dom: is dominant node
id: intermeiate dominat is like parent
DxD is like the tuples within different nodes.
DxDxD is like the triple.
A node cannot have two dominant nodes, cuz that the dominant of two nodes with each other is not exsist.
We can use first order logic to discuss the linguistics syntax structure.
Narrow-band filter just have fine resolution in frequency. Low damping. 45Hz
Wide-band filter can have poor resolution in frequency. for formants features. The energy disperse very quickly, loss the energy quicker. High damping. 300Hz
Rectification: Make the voltages more steady.
Multi-speech
Man voice is easier to analyze from history, lower formants, lower frequencies.
Window is like 256, Frame is always like 25ms. Rectangle windowing is a way how we do framing into seconnds.
DFT is like the sampled version of the DTFT.
m? Window length of the FFT??
0Hz frequency is just the
Frame and $\delta$
DFT leakage is causing cuz we assumeed before the speech data is periodic, but its not so there had some problems, if the signal is not period at all.
FFT is reducing the reducdent value like, the N must be a power of 2, it is much faster.
Longer seuqnecy = better frequency (Bigger N)
Shorter sequence = better time resoltion (Small N)
Convoltuion with the windowing function with the fft
Zero padding is just to add more 0's make the windowing length
When you do the windowing, so what we do is exactly is set other signals outside the windowing is "0".
The N of sampling, N input, out DFT, still the N output.
Zero padding is not about the resolution, is to get the peaks and slope more easily.
Zero padding is used all the time?
THe drawback of zero-padding, short window DFT, longer window DFT, longer window takes more time, just take time.
The points we measure each time can change since the decibel value there always make no sense, just ignore it, even if we just remove a little bit.
We usually use the 10th hamonics, so we divide 10 to get the f0 harmonic value, the reason is the 10 is easy to average the fundamental frequency.
The N value is very important, and it really can define anything.
FFt sizes = framming length = windowing length, for eample if we have 512 FFT points.
512/sampling frequnecy = ms
Glottal Pulse can be happened very close to f0 and attemps you to choose it as F1. The spectrogram resolution can be defined the vocal tract vibration cycle.
like 600 points , 30 Hz: Narrow band
like 100 points , 200 Hz: Wide band
Advanced spectrogram setting in Praat they can use Gaussian windowing, its not quite totally Gussian in there since we still need to choose the limited range of that windowing Guassian. SO they are many kinds of Gaussian windowing functions.
Choose the N length => add windowing function.
T test is for finding the two numerical data difference, X^2 test is applied to the two categorical data.
We only can say statistically different, we cannot say 100% different. What can we do is to do sampling first and guessing. Anova can help us find more statistics difference like many different T test at the same time. Log linear analysis for multiple X^2 test .
Pitch is not really supposed to measure in Hz. Its not only depend on the frequency, it can be mel. Mel is a musical term, 1KHz = 1K Mel, its a pyschoacoustics stuff.
If we raise the pitch twice time on mel, but we need more frequency.
Why say pitch is very closed to frequency is only like under 1Khz, they are propotional. Its better fitness like lower frequency and mel scale.
Bark is the simplication of the critical bandwidth.
You can also pitch from aperidoic like noise and so on.
Mel scale is based on percetpual test.
Pitch will play a important role in the f0 tracking.
Auditory Demostration CD booklet Demostration 25. Analytic vs. Synthetic Pitch.
Ohms Acoustic law.
**McGurk Effect (Acoustic and Visual information)**
AUditoary illuustion in BBC
Light collector to paint the spectrogram.
Carrier phrase is just a phrase over and over again, "say again..."
Glides for dipthongs.
Coarticulations
Formants are the resounance of the vocal tract. We do have formants in constants. But for vowels the formants are more clearly. The transitions of the formants can also be an acoustic cue.
F1: 300~500 Hz
F2: 800~2000 Hz or even
F3: very higher
Cross mode is very hard to let us to explore the cross-sectonal area, so it will not be a very imporant cue for us, it is less predictable. Cross-mode can affect the higher freq very much, and especially for F4 or even F5, and F4 and F5 values. Its true the cross-sectional area will affect the vowel quality but not that important and possible for us to research.
Spectrum contour : envelope?
There is no one-to-one from articulation to acoustics.
LPC is model based approach, which is different from DFT.
LPC: the sample can be predicted by the previous speech sample with a few factors. $a_{k}$ in here is coefficients, and error function.
Impluse train: very tinny pulse time like even less than one 1%, it can gets the harmonics, and all the harmonics have the same amplitude. It can be infinetly narrow.
Random noise can be random white noise, and all the hamonic have the same amplitude, and its very flat.
H(z): the z can be a frequency domain representation.
U(z): is source always used as source
H: Transfer function always used
S: is just the output signal, it used capital letter as the frequency domain
Frames the things will not change drammatically.
Intensity or energy is proportional square of the the signal.
p?
square? What if without square?
N+p-1?
p is ten, we just make E as small as possible.
We always deal with the energy error?
We have frame of data, we compute all those value.
Diagonal is the diagonal direction is all the value are the same, so it is constanct.
Stable filter will at the time will reach 0, the decay of it will be the formant bandwidth, and will be positive bandwidth. Narrow band, declay slowly, always negative bandwidth. the narrow, the decaly is quickly cuz the energy loss. and constant will be constant, the unstable will be lounder and lounder over time, its not happened in speech usually.
Frame in here means the u take the DFT specturm length, but mostly the same like it was on the time domain.
If u just pick one steady point, it will not harm that much correlated about the N windowing length.
EEG signal, closed or open phase analysis, and closed one, when the vocal tract is closed.
Unform tube, there is no variation of the tube shape.
10Khz Sampling frequency => we can get the 5Khz limit => 1Khz one resonce => 5 resounces => 5*2 at least coefficients
**10Khz => at least 10 coeeficientts, mostly divide kHz, but actually its more than that result maybe few more.**
SHorter vocal tract, less coefficients.
Formants also can called like pole, cause it can cause peak on the spectrum.
Preemphasis mostly add 6dB/Octave to speech.
LPC expects a flat spectrum, so if we added the pre-empasis we look forward to have to that.
Power spetrum is cuz u still need to take the log and get the dB scale.
The LPC is about minimize the error fucntion.
Specturm contour will have more details if we increase the p value.
what the window length? what is the windowing function?
Nasal murmur: which is moslty in the low freq domain.
Vowels are more strong compared with nasal sounds, since vowels are more robust than the other ones, the interferences from the environment.
F2 and F3 coming together for avelor is called avelor pinch.
Stops showed a non-linearity perception effects. Stops are all closed, the mouth are closed.
Voice bar: the silence interval
Particularlly for voiceless stops: we care much about the burst.
Front vowel: higher F2
locus theory can explain the acoustic starting point, its like a point disperse from that place.
F2' : means the F2 we used is higher than the real f2.
When we determine the voiced, we talk about the vowels mostly since the vocal fold is vibrating. But it does not play a strong cue, its not sufficient. SO for English, like stops can be dertimined by voiceless or voiced from the VOT.
The VOT is longer, you will get more aspiration noise.
F1 cutback, cut some periodic engery of those vowels. SO thats the F1 weaking
**Formants can be dicussed by formants frequency and formant bandwidth. WIth broadbandwith, the amplitude will drop, with widering the bandwith the weaker energy we got.**
Long VOT, more widering time of the vocal tract, the weakening of the F1.
Fricatives is produced from the narrow space from the vocal tract, the air is very quickly.
Consistency: stability vowels means
Intensity higher then its more robust than other sounds, which is more stable thats also why vowels are more stable.
Identification test: ask listeners to write what they indicated to hear, open response, write down whatever they want, but mostly experiment used the forced choice way. Which are very limited answer.
Discrimination test: ABX test, you hear one stimulus, and then u hear B stimulus, and then listen X to ask if the sound is more close to a or B. If you did ABX, you can only guess. When it close to 50%, that we can say the A and B can be hearly differently. Two step means from no 1~3 and 3~5 not one step like one to one next. The aim is to get the clear categorical differences.
CVC context: constants, vowel, constants
IF we deal something rapidly changing, then we can have the categorical change for vowels. Longer duration for vowels, less categorical.
**Voice quality is not really categorical in some way. U already have bias the people who set up the test samples, it is overlapped with the listeners bias. How we control the varible. Johh Lay auditory colouring, artiuculary voice source. Voice source, soft breathy voice, very lax, creaky phoneticial, wispering all those shades emotional. Laverys different people use different ways, impressionistic John lavery tried to give the unified way.**
Vision can overide the human audtory.
70s, expert system, a lot of cues to do phonetics or speech recognition.
The purpose of understanding speech perception is not to build of ASR.